|
���x�W퓵ı��|���dz����ı���ӛ�Z�ԣ�ͨ�^�Y��ʹ��������Web���g���磺�_���Z�ԡ������W�P�ӿڡ��M���ȣ������Ԅ����������ľW퓡�����������ı���ӛ�Z�����f�S�W��Web�����̵Ļ��A��Ҳ�����f�f�S�W�ǽ���... �W퓵ı��|���dz����ı���ӛ�Z�ԣ�ͨ�^�Y��ʹ��������Web���g���磺�_���Z�ԡ������W�P�ӿڡ��M���ȣ������Ԅ����������ľW퓡�����������ı���ӛ�Z�����f�S�W��Web�����̵Ļ��A��Ҳ�����f�f�S�W�ǽ����ڳ��ı����A֮�ϵġ������ı���ӛ�Z��֮���ԷQ�鳬�ı���ӛ�Z�ԣ�������ı��а��������^������朽ӡ��c�� ��ƪ���½o��Ҏ����ă������P��Node��ܽ���ELK���^��С�Y����һ���ą����rֵ������Ҫ�����ѿ��ԅ���һ�£�ϣ�����������������҂������^�ϙC������־�Ľ��v������Ⱥ��������ĕr���@�Nԭʼ�IJ��������ĵ�Ч�ʲ��H�o�҂���λ�F�W���}����O�������ͬ�r���҂�Ҳ�o�����҂����տ�ܵĸ��ָ���M����Ч�������\�࣬���o��Մ��ᘌ��Եă������M���@���r�����߂���Ϣ���ң������\�࣬���������ȹ��ܵČ��r��־�O��ϵ�y�Ȟ���Ҫ�� ELK ��ELK Stack: ElasticSearch, LogStash, Kibana, Beats�� ��һ�׳������־��Q���������_Դ���������ڸ���˾�V��ʹ�á����҂��I����ʹ�õķ��տ�ܣ���ν��� ELK ϵ�y�أ� �I�ձ����҂��ĘI�տ�ܱ�����
���벽�E�҂���������ܽ��� ELK ���Κw�{������ׂ����E��
һ����־�Y���OӋ���y�ģ��҂�������־ݔ���ĕr����ֱ��ݔ����־�ĵȼ���level������־�ă����ַ�����message����Ȼ���҂����H�Pעʲô�r�g���l����ʲô������߀��Ҫ�Pע��Ƶ���־�l���˶��ٴΣ���־�ļ����c�����ģ��Լ��P����־�� ����҂���ֻ�Ǻ��ε،��҂�����־�Y����һ�錦��߀Ҫ��ȡ����־�P�I���ֶΡ� 1. ����־������¼��҂���ÿһ�l��־�İl���������һ���¼����¼������� �¼�Ԫ�ֶ��¼��l���r�g��datetime, timestamp �¼��ȼ���level�� ����: ERROR, INFO, WARNING, DEBUG �¼����Q: event, ���磺client-request �¼��l���������r�g����λ���{�룩��reqLife, ���ֶΞ��¼�����Ո���_ʼ�l���ĕr�g���g���� �¼��l����λ��: line�����aλ��; server, ��������λ�� Ո��Ԫ�ֶ�Ո��ΨһID: reqId, ���ֶ�؞������Ո���·�ϰl���������¼� Ո���Ñ�ID: reqUid, ���ֶΞ��Ñ����R�����Ը�ۙ�Ñ����L����Ո���· �����ֶ���ͬ��͵��¼�����Ҫݔ���ļ������M��ͬ���҂����@Щ��������Ԫ�ֶΣ��yһ�ŵ�d -- data��֮�С�ʹ�҂����¼��Y������������ͬ�r��Ҳ�ܱ��┵���ֶΌ�Ԫ�ֶ������Ⱦ�� e.g. �� client-init�¼���ԓ�¼�����ÿ�η��������յ��Ñ�Ո��r��ӡ���҂����Ñ��� ip, url���¼����еĽyһ�w�锵���ֶηŵ� d ������ �e������������ {
"datetime":"2018-11-07 21:38:09.271",
"timestamp":1541597889271,
"level":"INFO",
"event":"client-init",
"reqId":"rJtT5we6Q",
"reqLife":5874,
"reqUid": "999793fc03eda86",
"d":{
"url":"/",
"ip":"9.9.9.9",
"httpVersion":"1.1",
"method":"GET",
"userAgent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
"headers":"*"
},
"browser":"{"name":"Chrome","version":"70.0.3538.77","major":"70"}",
"engine":"{"version":"537.36","name":"WebKit"}",
"os":"{"name":"Mac OS","version":"10.14.0"}",
"content":"(Empty)",
"line":"middlewares/foo.js:14",
"server":"127.0.0.1"
}һЩ�ֶΣ��磺browser, os, engine��ʲô����� �Еr���҂�ϣ����־�M����ƽ�������Ȟ�2�����Ա��� ES ����Ҫ���������������ܓp�ġ��ڌ��Hݔ���ĕr���҂�������ȴ���1��ֵݔ�����ַ��������Еr��һЩ�����ֶ����҂��Pע�ģ������҂����@Щ�����ֶη�����ӣ��Ա��Cݔ����Ȳ�����2��ԭ�t�� һ��ģ��҂��ڴ�ӡݔ����־�ĕr��ֻ��Pע 2. ��־����ݔ��ǰ���҂��ᵽ����ζ��xһ����־�¼��� ��ô���҂���λ���������־������������ͬ�r�������f���a����־�{�÷�ʽ�� �����P�I���c����־// ����ǰ
logger.info('client-init => ' + JSON.stringfiy({
url,
ip,
browser,
//...
}));
// �����
logger.info({
event: 'client-init',
url,
ip,
browser,
//...
});�����f����־�{�÷�ʽlogger.debug('checkLogin');��� winston �� ��־����������֧�� string ���� object �Ă��뷽ʽ, ���Ԍ����f���ַ������댑����formatter ���յ��Č��H����{ level: 'debug', message: 'checkLogin' }��formatter �� winston ����־ݔ��ǰ�{����־��ʽ��һ������ �@һ�cʹ�҂�����־ݔ��ǰ�ЙC�����@��{�÷�ʽݔ������־���D��һ����ݔ���¼� -- �҂��Q������raw-log�¼���������Ҫ���{�÷�ʽ�� ������־ݔ����ʽǰ���ᵽ winston ݔ����־ǰ�������^�҂��A���x��formatter����˳��˼���߉��̎���⣬�҂����Ԍ�һЩ����߉�yһ�����@��̎�������{���ϣ��҂�ֻ�Pע�ֶα������ɡ�
�����ȡԪ�ֶΣ��@���漰�����ĵĄ����cʹ�ã��@�ﺆ�ν�Bһ�� domain �Ą����cʹ�á� //--- middlewares/http-context.js
const domain = require('domain');
const shortid = require('shortid');
module.exports = (req, res, next) => {
const d = domain.create();
d.id = shortid.generate(); // reqId;
d.req = req;
//...
res.on('finish', () => process.nextTick(() => {
d.id = null;
d.req = null;
d.exit();
});
d.run(() => next());
}
//--- app.js
app.use(require('./middlewares/http-context.js'));
//--- formatter.js
if (process.domain) {
reqId = process.domain.id;
}�@�ӣ��҂��Ϳ��Ԍ� ������־�ɼ��F�ڣ��҂�֪����ôݔ��һ���¼��ˣ���ô��һ�����҂�ԓ���]�ɂ����}��
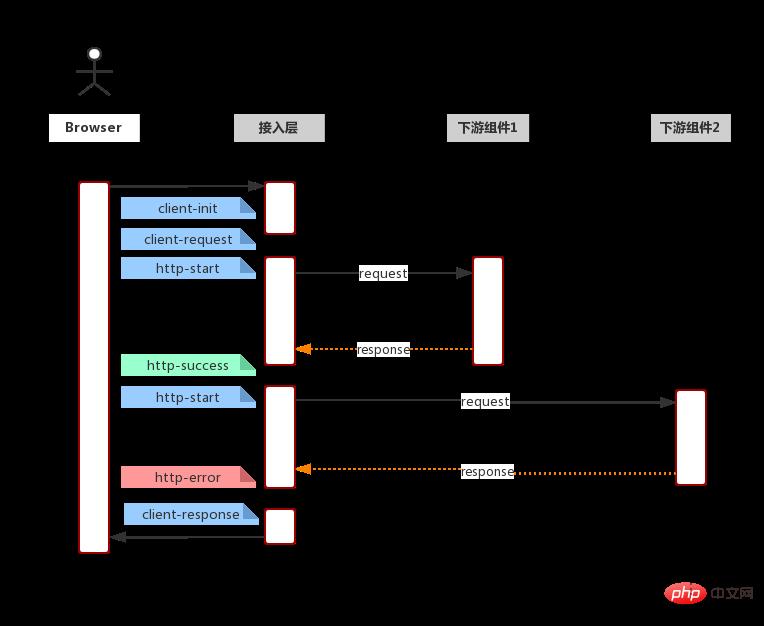
�Q��Ԓ�f������Ո���·�У���Щ���c���҂��Pע�ģ����F���}������ͨ�^�Ă����c����Ϣ���ٶ�λ�����}������֮�⣬�҂�߀����ͨ�^��Щ���c�Ĕ������yӋ������ �Y��һ�㳣Ҋ��Ո���·���Ñ�Ո���ՂȽ���Ո����Ո�����η�����/�����죨*��Σ��������ۺ���Ⱦ������푑��������·������̈D
��ô���҂������@�Ӷ��x�҂����¼��� �Ñ�Ո��client-init: ��ӡ�ڿ�ܽ��յ�Ո��δ�������� ������Ո���ַ��Ո���^��Http �汾�ͷ������Ñ� IP �� �g�[�� client-request: ��ӡ�ڿ�ܽ��յ�Ո���ѽ�������������Ո���ַ��Ո���^��Cookie, Ո����w client-response: ��ӡ�ڿ�ܷ���Ո������Ո���ַ��푑��a��푑��^��푑����w ������هhttp-start: ��ӡ��Ո��������ʼ��Ո���ַ��Ո����w��ģ�K�e��������������־ۺ϶��������� http-success: ��ӡ��Ո�� 200��Ո���ַ��Ո����w��푑����w(code & msg & data)���ĕr http-error: ��ӡ��Ո�ط� 200���༴�B�ӷ�����ʧ����Ո���ַ��Ո����w��푑����w(code & message & stack)���ĕr�� http-timeout: ��ӡ��Ո���B�ӳ��r��Ո���ַ��Ո����w��푑����w(code & msg & stack)���ĕr�� �ֶ��@ô�࣬ԓ��ô�x�� һ���Ա�֮���¼�ݔ�����ֶ�ԭ�t���ǣ�ݔ�����Pע�ģ�����z���ģ�������ھۺϵ��ֶΡ�һЩ���h
һЩԭ�t
����ES ����ģ�涨�x�@������ ES �ăɂ����ӳ��(Mapping)�cģ��(Template)�� ���ȣ�ES �����Ĵ惦��ʹ��ö�e�£������N
һ��ģ��҂�����Ҫ�@ʾָ��ÿ���¼��ֶε���ES�����Ĵ惦��ͣ�ES ���ԄӸ����ֶε�һ�γ��F��document�е�ֵ��Q���@���ֶ����@�������еĴ惦��͡����Еr���҂���Ҫ�@ʾָ��ijЩ�ֶεĴ惦��ͣ��@���r���҂���Ҫ���x�@�������� Mapping, �����V ES �@���ֶ���δ惦�Լ���������� e.g. ߀ӛ���¼�Ԫ�ֶ�����һ���ֶΞ� timestamp �����H�ϣ��҂�ݔ���ĕr��timestamp ��ֵ��һ�����֣�����ʾ�����x 1970/01/01 00:00:00 �ĺ��딵�����҂���������ES�Ĵ惦��͞� date ��ͷ�����ڵęz���Ϳ�ҕ��, ��ô�҂����������ĕr��ָ���҂���Mapping�� PUT my_logs
{
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "date",
"format": "epoch_millis"
},
}
}
}
}��һ��ģ��҂����ܕ��������Ԅ������҂�����־�������ٶ��҂����������Q��ʽ�� my_logs_yyyyMMdd ��e.g. my_logs_20181030������ô�҂���Ҫ���xһ��ģ�壨Template�����@��ģ����ڣ�ƥ��ģ����������r�Ԅӑ����A�O�õ� Mapping�� PUT _template/my_logs_template
{
"index_patterns": "my_logs*",
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "date",
"format": "epoch_millis"
},
}
}
}
}��ʾ�����������ڮa������־������һ�������У����H��������Ҫ�������_�N��Ҳ�����ڶ��ڄh�����^���h����־��С�Y ���ˣ���־���켰����Ĝʂ乤�����ѽ�����ˣ��҂�ֻ��ڙC���ϰ��b FileBeat -- һ���p�������ļ���־Agent, ��ؓ؟����־�ļ��е���־��ݔ�� ELK���������҂����ʹ�� Kibana ���ٵęz���҂�����־�� ���Ͼ���Node��ܽ���ELK���^��С�Y��Ԕ�����ݣ�����Ո�Pעphp���ľW�������P���£� �Wվ���O��һ���V�x���g�Z�����w���S�ͬ�ļ��ܺ͌W������ʹ�õ����a�;S�o�ľWվ�� |
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l����Win7������ϵ�y��Win10�������XP������ϵ�y�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�(peng896066052@126.com),�҂������r̎��.
Copyright © 2018-2020 ����ľ�L���dվ