|
���x�W퓵ı��|���dz����ı���ӛ�Z�ԣ�ͨ�^�Y��ʹ��������Web���g���磺�_���Z�ԡ������W�P�ӿڡ��M���ȣ������Ԅ����������ľW퓡�����������ı���ӛ�Z�����f�S�W��Web�����̵Ļ��A��Ҳ�����f�f�S�W�ǽ���... �W퓵ı��|���dz����ı���ӛ�Z�ԣ�ͨ�^�Y��ʹ��������Web���g���磺�_���Z�ԡ������W�P�ӿڡ��M���ȣ������Ԅ����������ľW퓡�����������ı���ӛ�Z�����f�S�W��Web�����̵Ļ��A��Ҳ�����f�f�S�W�ǽ����ڳ��ı����A֮�ϵġ������ı���ӛ�Z��֮���ԷQ�鳬�ı���ӛ�Z�ԣ�������ı��а��������^������朽ӡ��c�� ��ƪ���½o��Ҏ����ă����ǽ�Bpuppeteer���x��ʲô�����x�Ĺ���ԭ������һ���ą����rֵ������Ҫ�����ѿ��ԅ���һ�£�ϣ�����ゃ�������������x��puppeteer����ʲô�� ���x�ַQ�W�j�C���ˡ�ÿ����S�㶼��ʹ���������棬���x��������������Ҫ�ĽM�ɲ��֣���ȡ�������������F���������������ܻ��ǔ���������أ�����ͨ�^�W�j���x��ȡ���������Ⱦ́�̽ӑһ�¾W�j���x�ɡ�
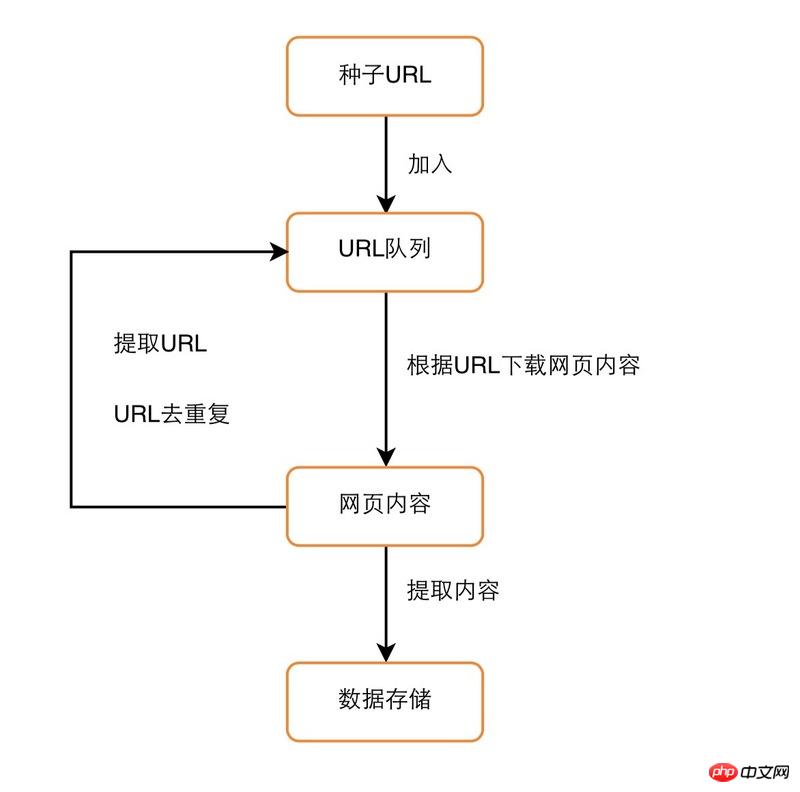
���x�Ĺ���ԭ�� ��D��ʾ���@�����x�����̈D�����Կ���ͨ�^һ���N��URL�_�����x����ȡ֮�ã�ͨ�^���d�W퓣������W��Ѓ��ݴ惦��ͬ�r�����оW��е�URL ȥ���؏ͺ���뵽�ȴ���ȡ����С�Ȼ��������ȡ����һ���ȴ���ȡ��URL�؏����ϲ��E���Dz��Ǻܺ����أ� �V�ȣ�BFS��߀����ȣ�DFS�����Ȳ��� ����Ҳ�ᵽ����ȡ��һ���W퓺�ĵȴ���ȡ��������xȡһ��URLȥ��ȥ��������x���أ����x��ǰ��ȡ�W��е�URL ߀���^�m�xȡ��ǰURL��ͬ��URL�أ��@���ͬ��URL��ָ����ͬһ���W퓵�URL���@������ȡ����֮�֡�
�V�ȃ��Ȳ��ԣ�BFS�� �V�ȃ��Ȳ��Ա��nj���ǰij���W���URL����ȡ��ȫ����ȥ��ȡ�Į�ǰ�W��е�URL��ȡ��URL���@����BFS������ψD���Pϵ�D��ʾ�W퓵��Pϵ����ôBFS����ȡ���Ԍ����ǣ���A->(B,D,F,G)->(C,F)); ��ȃ��Ȳ��ԣ�DFS�� ��ȃ��Ȳ�����ȡij���W퓣�Ȼ���^�mȥ��ȡ�ľW��н�������URL��ֱ����ȡ�ꡣ ���d�W� ���d�W퓿������ܺ��Σ������ڞg�[����ݔ��朽�һ�ӣ����d���g�[�������@ʾ��������Ȼ�Y���Dz������@�ӵĺ��Ρ� ģ�M��� ����һЩ�W퓁��f��Ҫ��䛲��ܿ����W��Ѓ��ݣ������x��ô����أ��䌍��䛵��^�̾��ǫ@ȡ�L���đ{�C��cookie,token...) let cookie = '';
let j = request.jar()
async function login() {
if (cookie) {
return await Promise.resolve(cookie);
}
return await new Promise((resolve, reject) => {
request.post({
url: 'url',
form: {
m: 'username',
p: 'password',
},
jar: j
}, function(err, res, body) {
if (err) {
reject(err);
return;
}
cookie = j.getCookieString('url');
resolve(cookie);
})
})
}�@���ǂ����ε����ӣ���䛫@ȡcookie, Ȼ��ÿ��Ո����cookie. �@ȡ�W퓃��� �еľW퓃����Ƿ��ն���Ⱦ�ģ��]��CGI�܉�@�Ô�����ֻ��html�н������ݣ������еľWվ�ă��ݲ����Ǻ��εı��ܫ@ȡ���ݣ���linkedin�@�ӵľWվ�����Ǻ��ε��܉�@�þW퓃��ݣ��W���Ҫͨ�^�g�[�����к���ܫ@����K��html�Y��������ô��Q�أ�ǰ�������ᵽ�g�[�����У���ô�����Л]�пɾ��̵Ğg�[���أ�puppeteer,�ȸ�chrome�F��_Դ�ğo�^�g�[���Ŀ�����ßo�^�g�[������ģ�M�Ñ��L�������ܫ@ȡ���ؾW퓵ă��ݣ�ץȡ���ݡ� async function login(username, password) {
const browser = await puppeteer.launch();
page = await browser.newPage();
await page.setViewport({
width: 1400,
height: 1000
})
await page.goto('https://example.cn/login');
console.log(page.url())
await page.focus('input[type=text]');
await page.type(username, { delay: 100 });
await page.focus('input[type=password]');
await page.type(password, { delay: 100 });
await page.$eval("input[type=submit]", el => el.click());
await page.waitForNavigation();
return page;
}���� async function crawlData(index, data) {
let dataUrl = `https://example.cn/company/contacts?count=20&page=${index}&query=&dist=0&cid=${cinfo.cid}&company=${cinfo.encodename}&forcomp=1&searchTokens=&highlight=false&school=&me=&webcname=&webcid=&jsononly=1`;
await page.goto(dataUrl);
// ...
}���еľWվ�����^��ÿ����ȡ��cookie��һ�ӣ�Ҳ�����ßo�^�g�[��ȡ��ȡ���@��ÿ�ξͲ���ÿ����ȡ�ĕr�����cookie. ������� ��Ȼ���x���H�H�@Щ��������nj��Wվ�M�з������ҵ����m�����x���ԡ������P�� ���Ͼ���puppeteer���x��ʲô�����x�Ĺ���ԭ����Ԕ�����ݣ�����Ո�Pעphp���ľW�������P���£� �Wվ���O��һ���V�x���g�Z�����w���S�ͬ�ļ��ܺ͌W������ʹ�õ����a�;S�o�ľWվ�� |
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l����Win7������ϵ�y��Win10�������XP������ϵ�y�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�(peng896066052@126.com),�҂������r̎��.
Copyright © 2018-2020 ����ľ�L���dվ